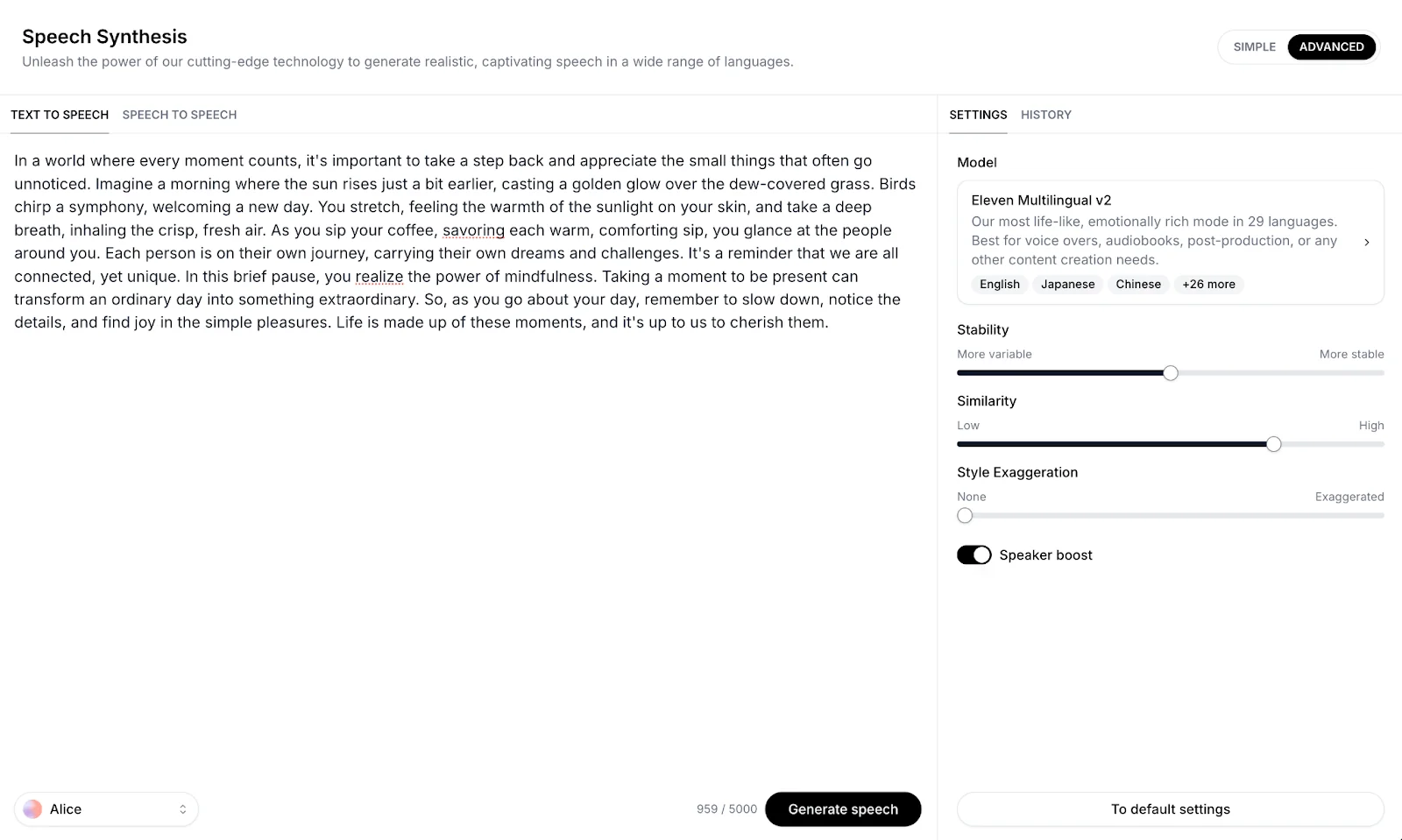
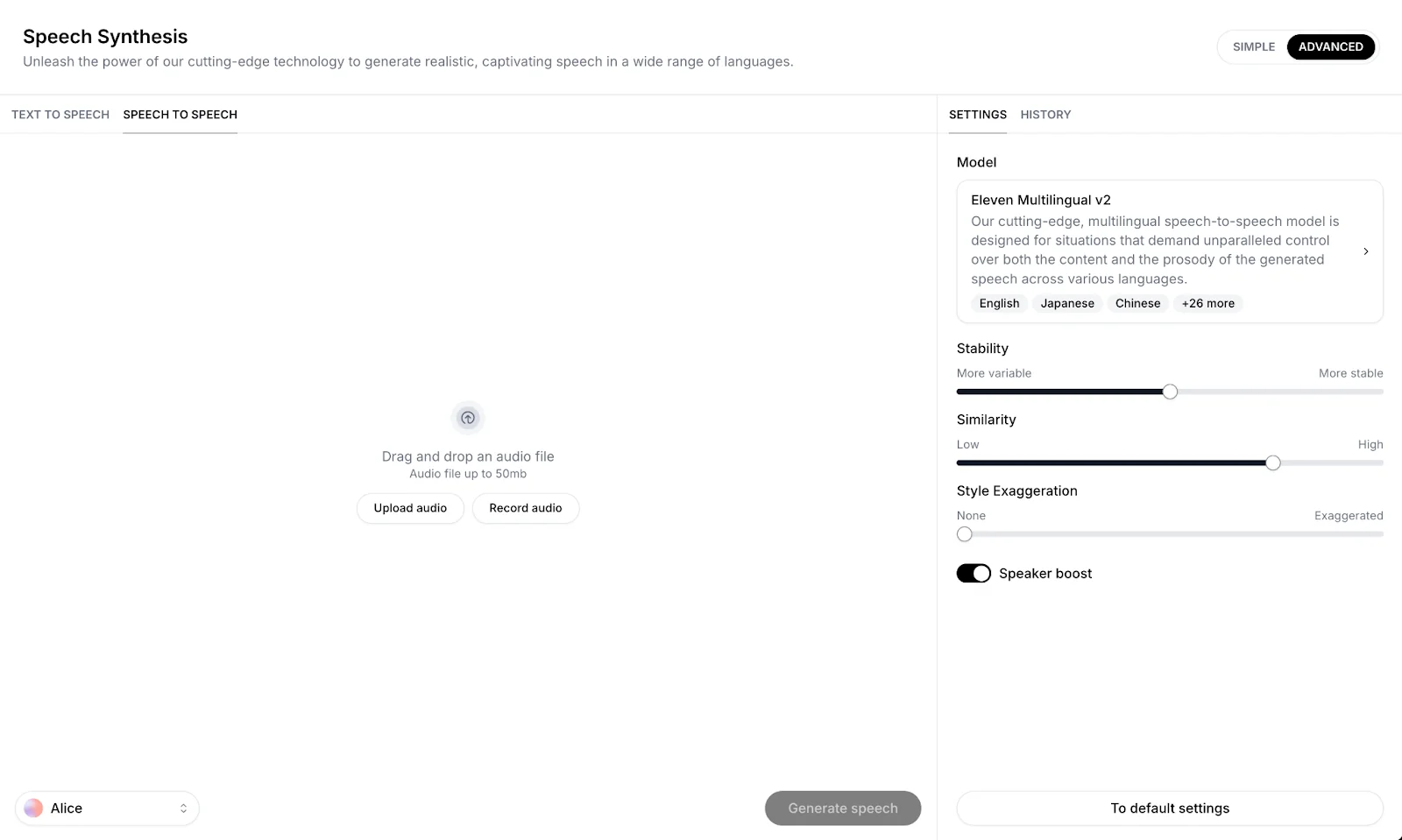
Speech Synthesis allows you to generate lifelike speech from text (Text to Speech) or audio (Speech to Speech) inputs. In this section, you can also see your generation history and thus retrieve past generations.
Selecting Advanced Mode allows you to select the model you would like to use for your generation as well as the voice settings (Stability, Similarity, Style, and Speaker Boost) on top of the existing options with Standard.
Let’s touch on models and voice settings briefly before generating our audio clip.
Models
More detailed information about the models is available here.
- Multilingual v2 (default): Supports 28 languages, known for its accuracy and stability, especially when using high-quality samples.
- Turbo v2.5: Generates speech in 32 languages with low latency, ideal for real-time applications.
- Turbo v2: Optimized for low-latency English text-to-speech, similar in performance to Turbo v2.5.
- English v1: The oldest and fastest model, best for audiobooks but less accurate.
- Multilingual v1: Experimental, surpassed by Multilingual v2, recommended for short text chunks.
Voice Settings
More detailed information about the voice settings is available here.
- Stability: Adjusts the emotional range and consistency of the voice. Lower settings result in more variation and emotion, while higher settings produce a more stable, monotone voice.
- Similarity: Controls how closely the AI matches the original voice. High settings may replicate artifacts from low-quality audio.
- Style Exaggeration: Enhances the speaker’s style, but can affect stability.
- Speaker Boost: Increases the likeness to the original speaker, useful for weaker voices.
Now that we understand models and voice settings a bit better, let’s jump into generating audio!
Text to Speech (TTS)
Step by step to Generate Text to Speech Audio
- Text Input: Type or paste your text into the input box on the Speech Synthesis page.
- Select Voice: Select the voice you wish to use from your Voices at the bottom left of the screen.
- Adjust Settings: Modify the voice settings for the desired output.
Generate: Click the ‘Generate’ button to create your audio file.
Exercise: Generate “All work and no play makes Jack a dull boy” using Alice’s voice (or a voice of your choosing).
Speech to Speech (STS)
Steps to Generate Speech to Speech Audio
- Audio Input: Upload or record audio via the input box on the Speech Synthesis page.
- Select Voice: Select the voice you wish to use from your Voices at the bottom left of the screen.
- Adjust Settings: Modify the voice settings for the desired output.
Generate: Click the ‘Generate’ button to create your audio file.
Speech to Speech is great for getting the right emotion across when the Text
to Speech can’t get it right.