Using Your Own OpenAI Key for LLM
To integrate a custom OpenAI key, create a secret containing your OPENAI_API_KEY:1
Navigate to the “Secrets” page and select “Add Secret”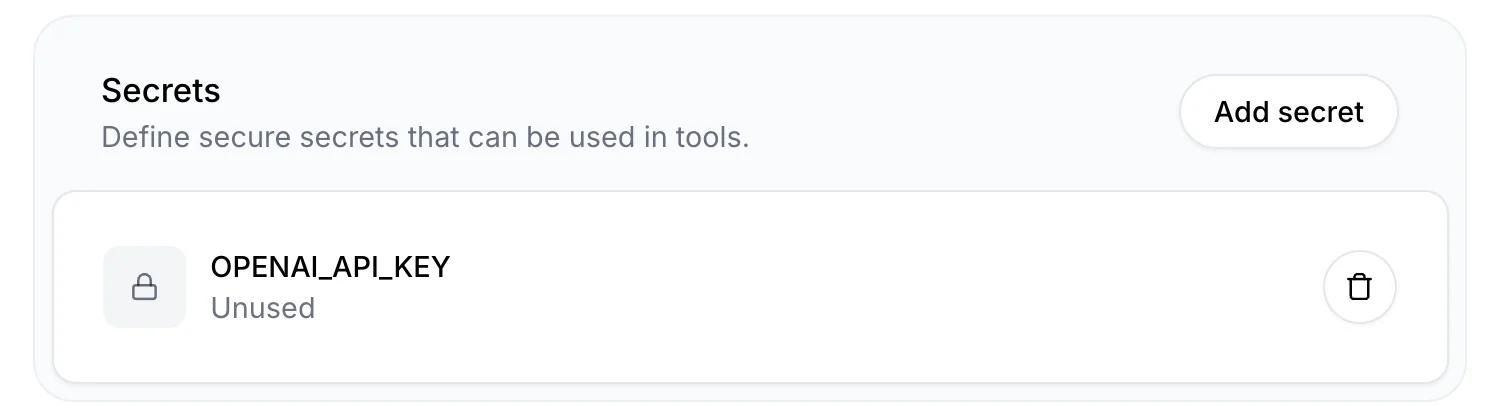
2
Choose “Custom LLM” from the dropdown menu.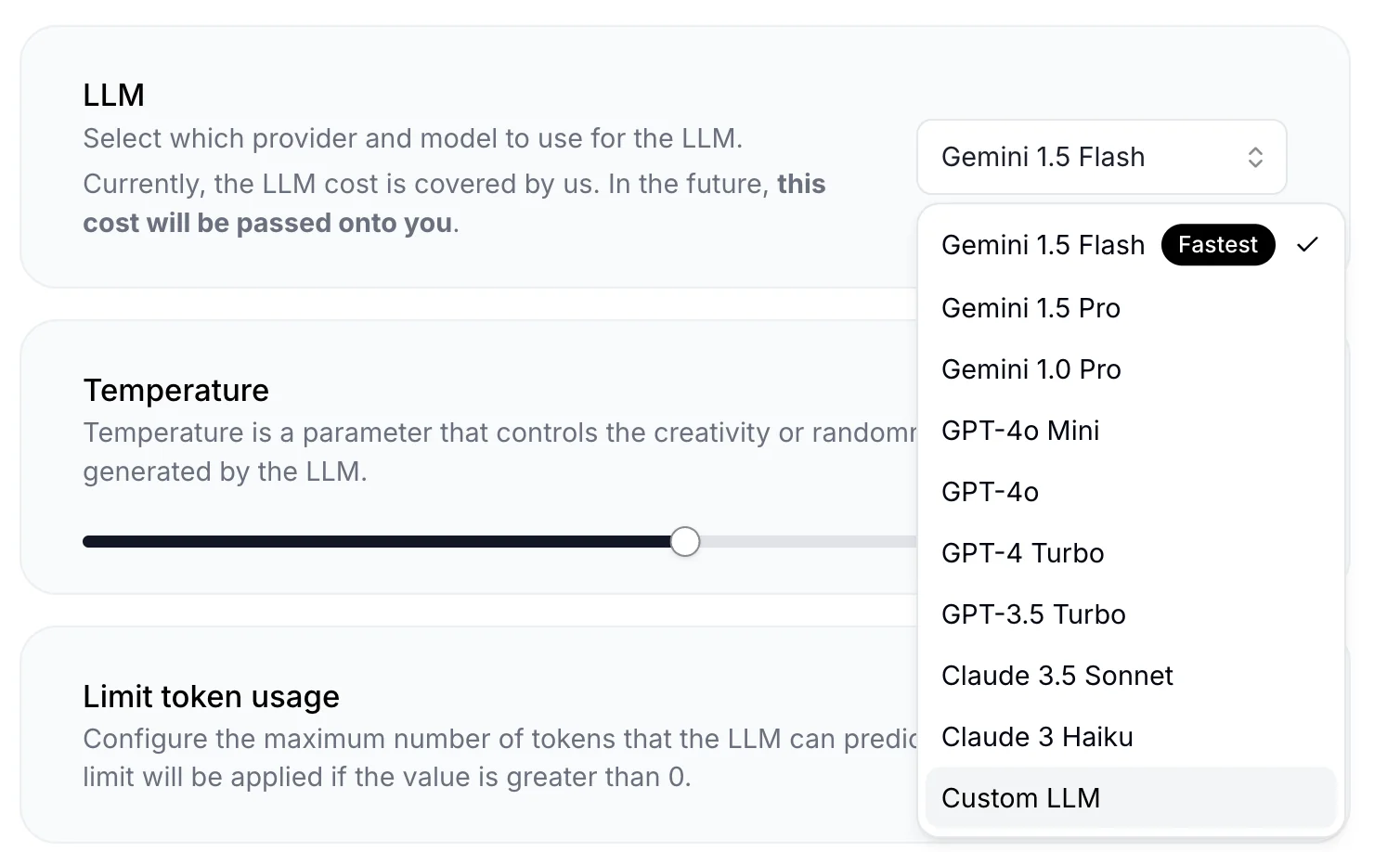
3
Enter the URL, your model, and the secret you created.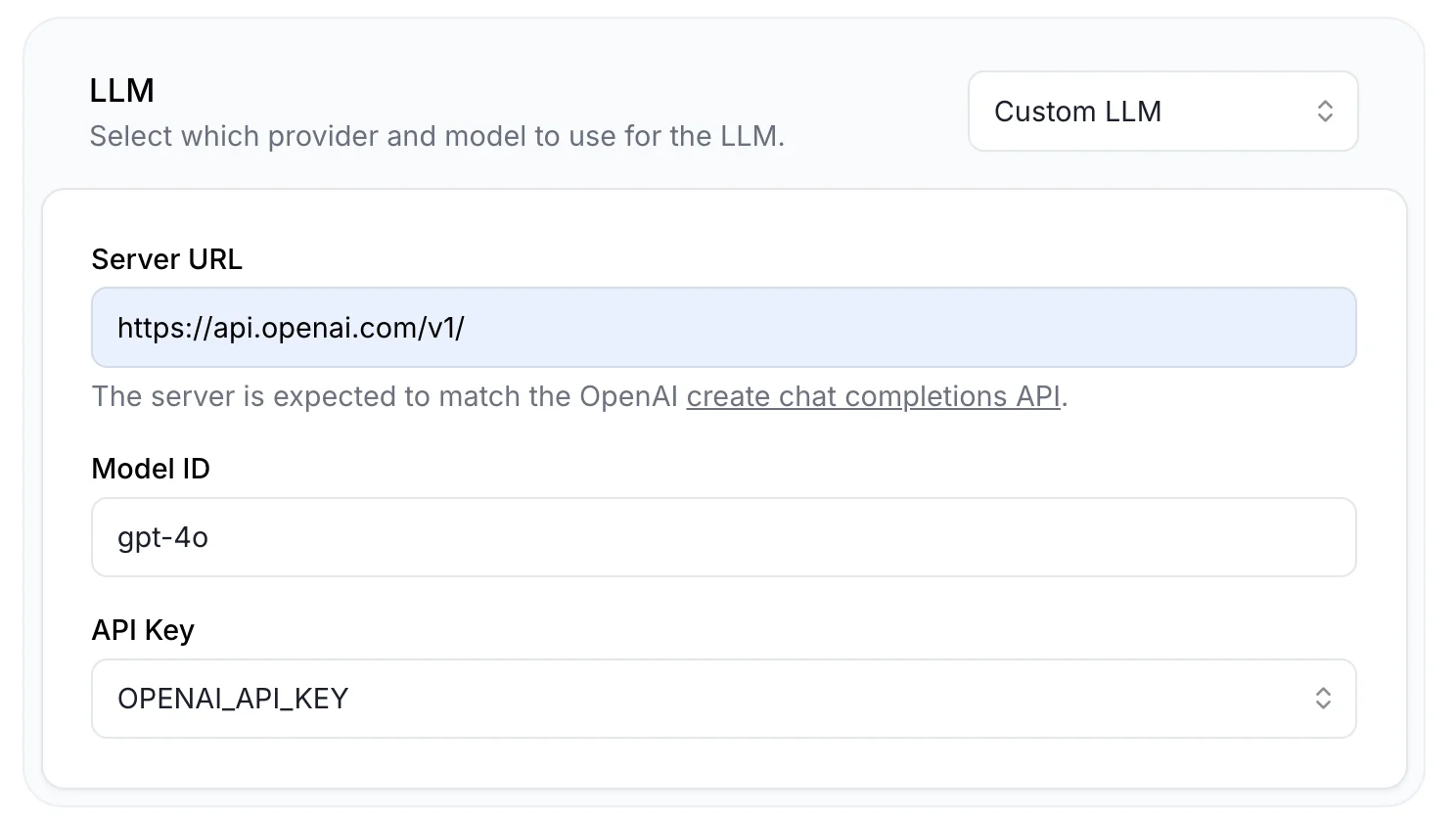
Custom LLM Server
To bring a custom LLM server, set up a compatible server endpoint using OpenAI’s style, specifically targeting create_chat_completion. Here’s an example server implementation using FastAPI and OpenAI’s Python SDK:
Setting Up a Public URL for Your Server
To make your server accessible, create a public URL using a tunneling tool like ngrok: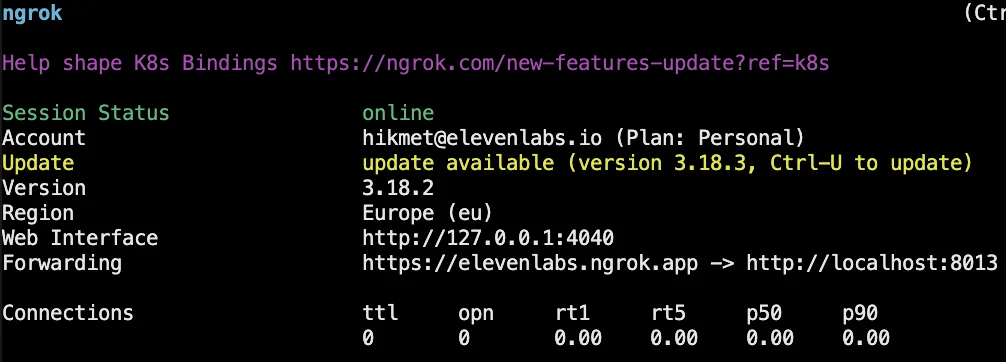
Configuring Elevenlabs CustomLLM
Now let’s make the changes in Elevenlabs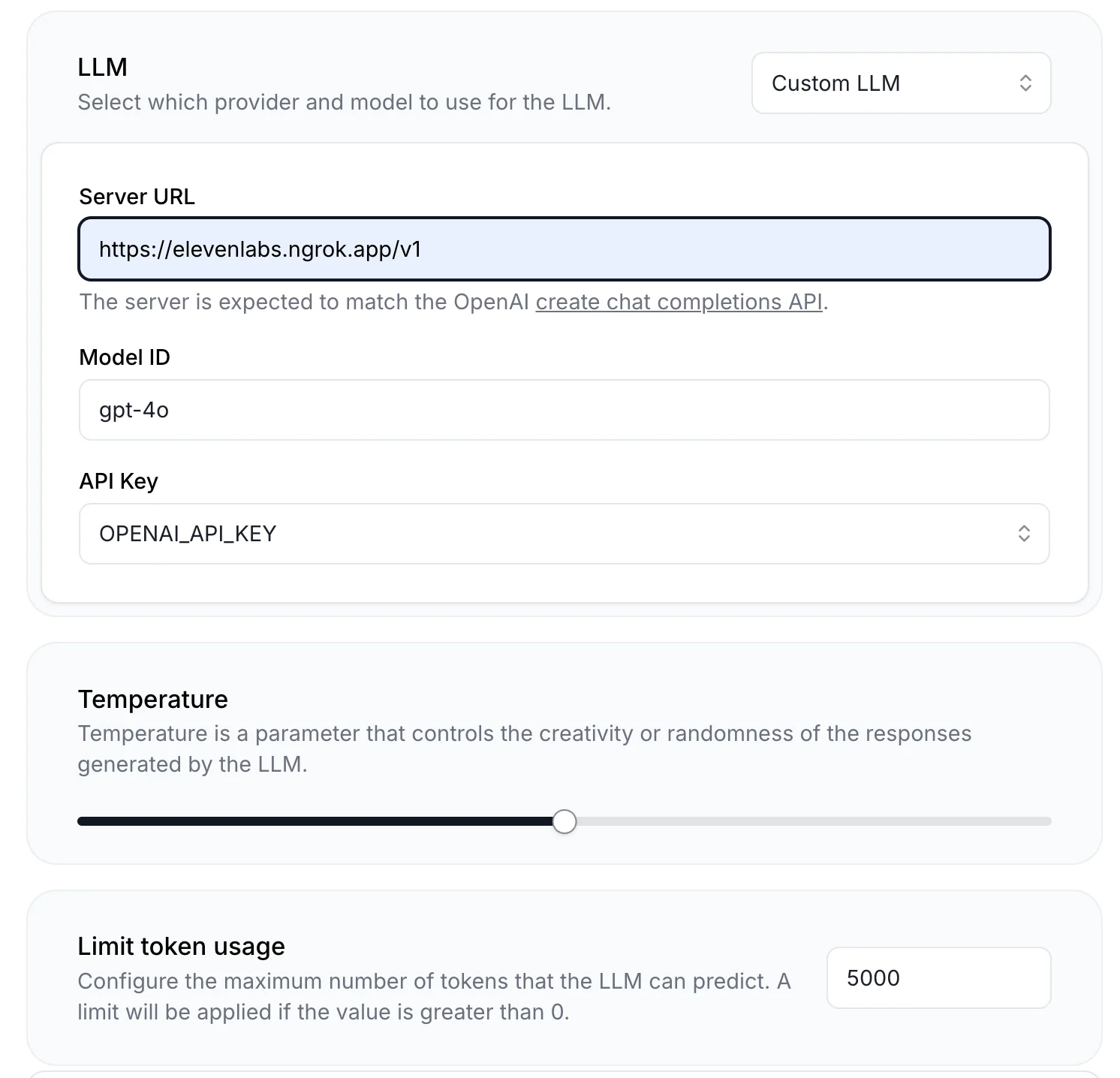
 Direct your server URL to ngrok endpoint, setup “Limit token usage” to 5000 and
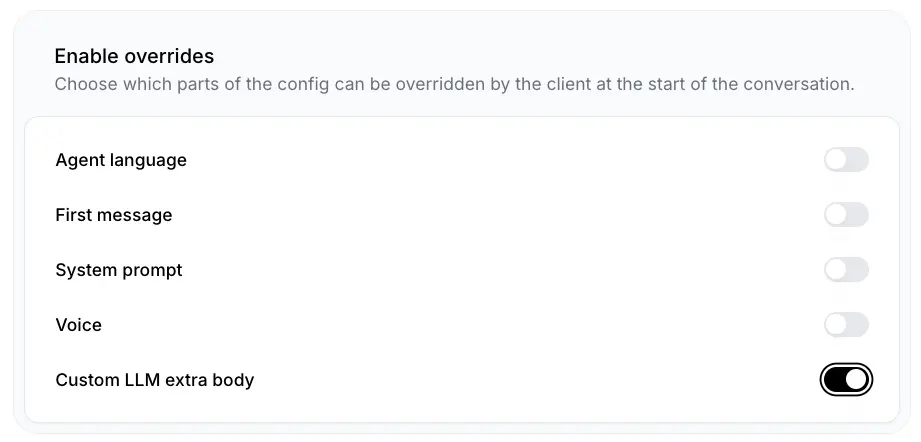
you can setup CustomLLM extra body to true if you want to pass additional parameters to your custom LLM implementation at conversation start.
You can start interacting with Conversational AI with your own LLM server
Direct your server URL to ngrok endpoint, setup “Limit token usage” to 5000 and
you can setup CustomLLM extra body to true if you want to pass additional parameters to your custom LLM implementation at conversation start.
You can start interacting with Conversational AI with your own LLM server
Additional Features
Custom LLM Parameters
Custom LLM Parameters
You may pass additional parameters to your custom LLM implementation.
- Python
1
Define the Extra Parameters
Create an object containing your custom parameters:
2
Update the LLM Implementation
Modify your custom LLM code to handle the additional parameters: